Parsing websites in C# with Html Agility Pack or AngleSharp
While developing the "new" canonical check feature for elmah.io Uptime Monitoring, I had to parse a website from C# and inspect the DOM. I have been using Html Agility Pack in the past so this was an obvious choice. I also looked at what happened in the space and found that AngleSharp is an excellent alternative. In this blog post, I'll showcase both frameworks to help you get started.
Before we start coding, let's talk about web scraping in general. The techniques presented in this post can be used to extract content from other people's websites. While you may think that publically available data can be consumed from code, this is often not the case. Most websites don't allow crawling their content and you may be violating copyright laws by doing so. Always make sure that web crawling is permitted and/or reach out to the company behind the website to make sure that scraping their content is allowed. With that out of the way, let's look at some code.
There are numerous tools and services providing web scraping capabilities from C#. With more than 100M downloads from NuGet, HtmlAgilityPack is the most popular one, closely followed by AngleSharp with almost 70M downloads (both numbers most likely increased since the writing of this post). For this demo, I'll show how to create a web scraping CLI with both frameworks, highlighting some of the main differences.
We'll be building a CLI showing price information about books. The CLI uses a service named Books to Scrape, which is a fictional bookstore that is intended for testing scraping tools.
Start by creating a new console application:
dotnet new console -n Books.Cli
Next, install the HtmlAgilityPack package (an example with AngleSharp is coming up in a few minutes):
dotnet add package HtmlAgilityPack
I'll also use Spectre.Console to make the CLI look pretty:
dotnet add package Spectre.Console
If you are not familiar with Spectre.Console it's an awesome tool including colors and widgets for CLIs. For more information, check out this post: Create a colored CLI with System.CommandLine and Spectre.
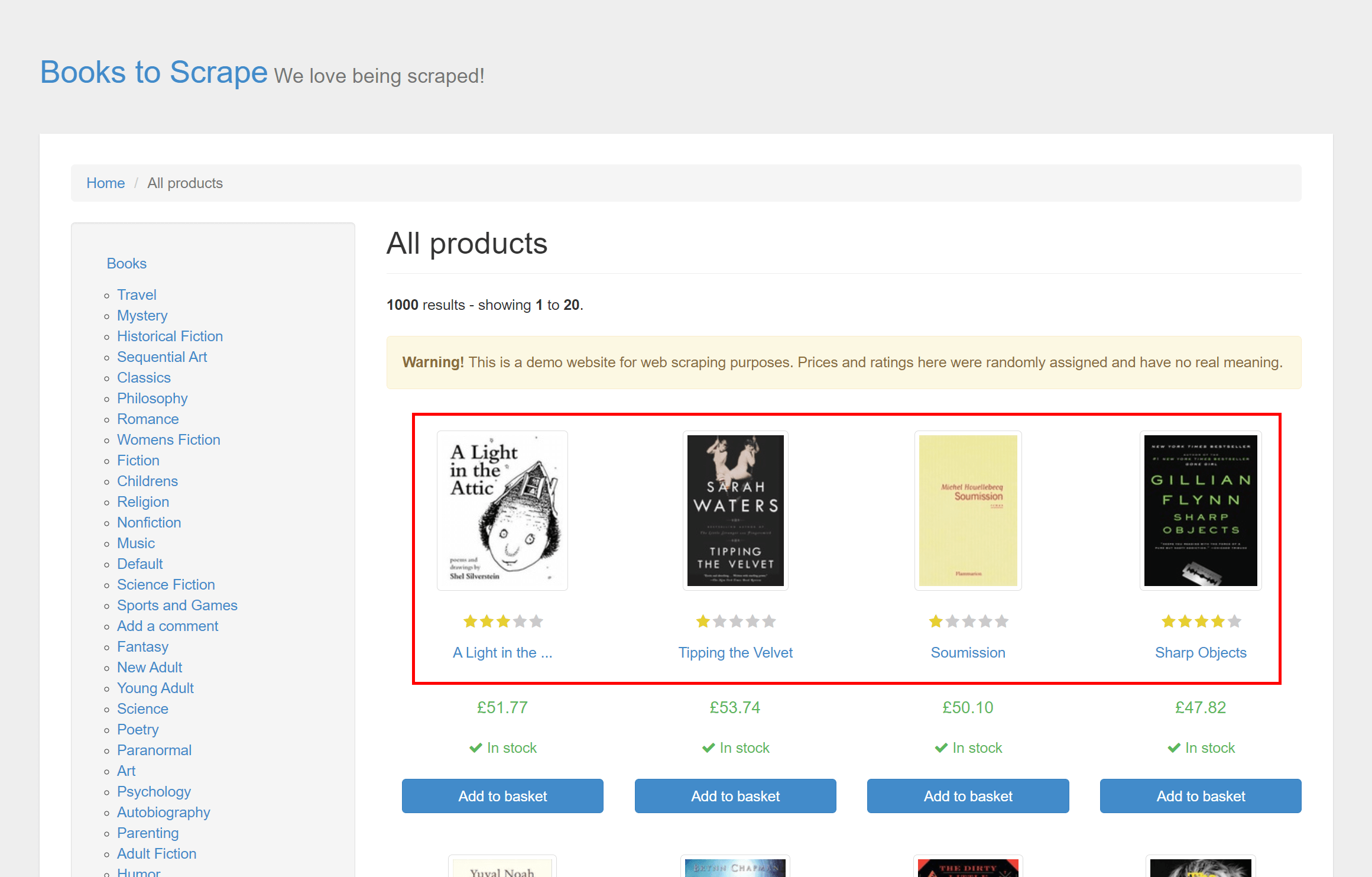
The CLI we'll create in this post will present a list of books available on the front page of Books to Scrape:
When the user selects a book, we'll make another request to the landing page of the back and fetch a price:
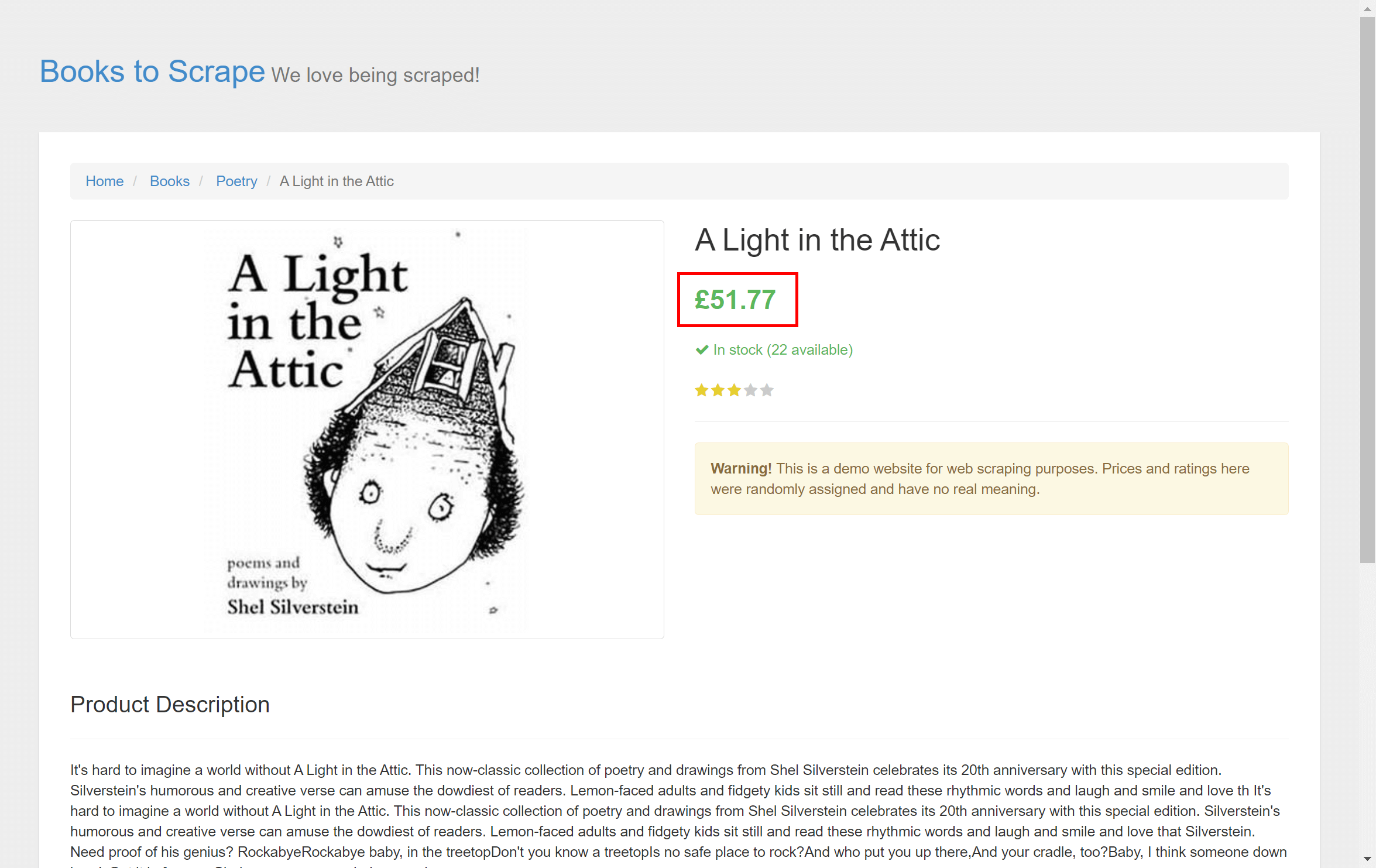
I know that the price is on the front page as well, but it will illustrate the scenario of parsing and navigating a website.
Start by creating a new HttpClient and fetching the front page:
var httpClient = new HttpClient
{
BaseAddress = new Uri("https://books.toscrape.com/")
};
var response = await httpClient.GetAsync("/");
var content = await response.Content.ReadAsStreamAsync();
HtmlAgilityPack provide a class named HtmlDocument which acts as the facade of the HTML content. Loading the stream from the HTTP client is easy:
var htmlDocument = new HtmlDocument();
htmlDocument.Load(content);
You can query the DOM using the HtmlDocument and you can even modify the content (not covered in this post). Queries are written using XPath which some people love and other people hate. There's an extension that will allow you to query a document using CSS selectors if you prefer that. I'll start by fetching the list of books and adding the title and URL to a dictionary:
var selections = new Dictionary<string, string>();
var books = htmlDocument.DocumentNode.SelectNodes("//article[@class='product_pod']");
foreach (var book in books)
{
var anchor = book.SelectSingleNode("div[1]/a");
var href = anchor.GetAttributeValue("href", string.Empty);
var image = anchor.SelectSingleNode("img[@class='thumbnail']");
var alt = image.GetAttributeValue("alt", string.Empty);
selections.Add(alt, href);
}
This is not an in-depth tutorial on XPath syntax. But //article[@class='product_pod'] basically means "Give me all <article> elements with a class attribute with the value product_pod. For each <article> element (a book) we'll select the anchor element to get the URL for the book, as well as the image element to get the title. You will need to inspect the markup of the site you are scraping to get this right. As an alternative, you can highlight the wanted element in the browser's Developer Tools, right-click, and copy the XPath:
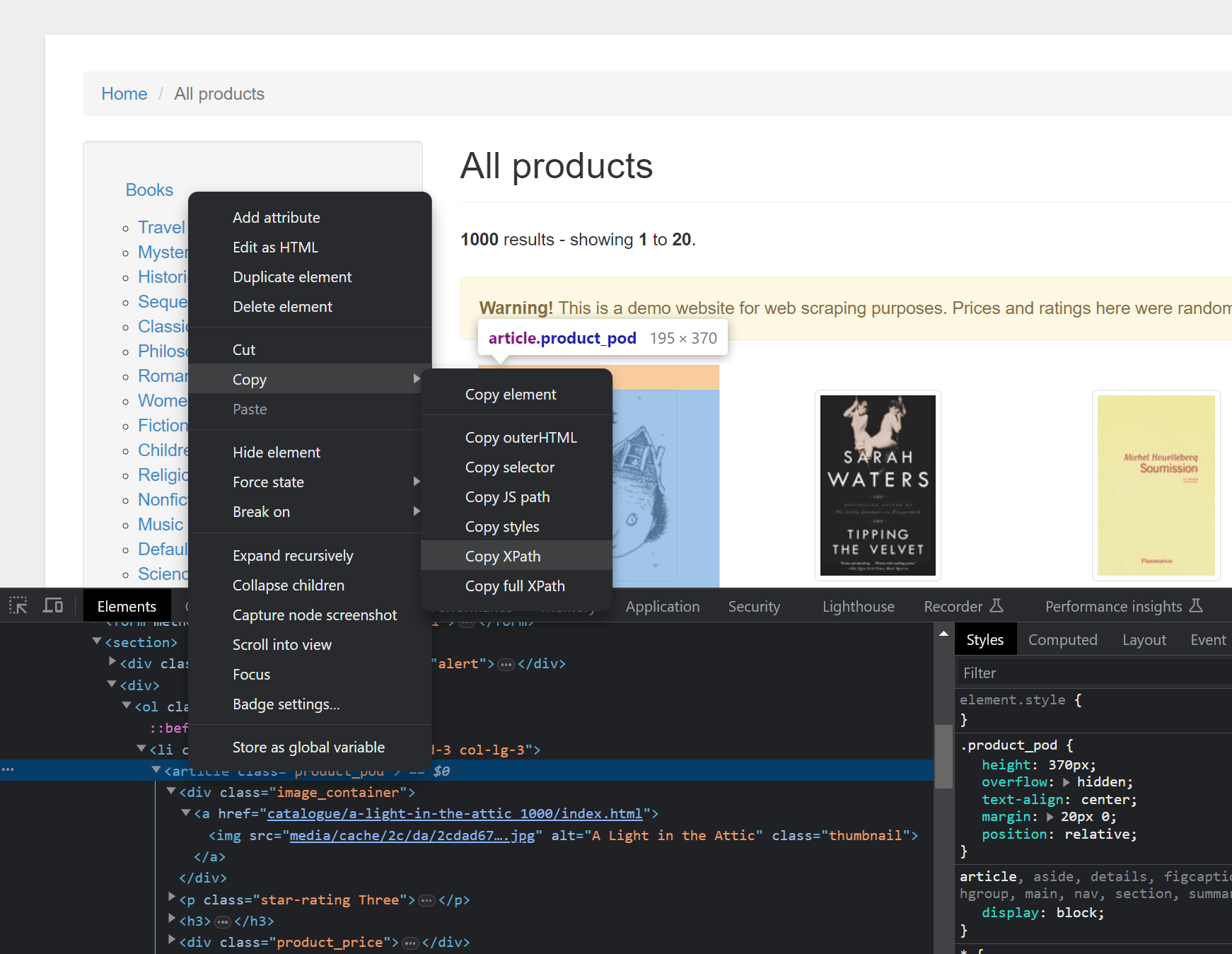
This will produce a rather long XPath expression, why an understanding of the XPath syntax is preferable here.
The next step is to present the user with the list of available books. We can use the Prompt widget from Spectre.Console to present all titles:
var selectedBook = AnsiConsole.Prompt(
new SelectionPrompt<string>()
.Title("Pick a book")
.PageSize(10)
.MoreChoicesText("[grey](Move up and down to reveal more books)[/]")
.AddChoices(selections.Keys));
When the user selects a book, the title is returned and stored in the selectedBook variable. We can use that to lookup the landing page for that book and inspect it with another XPath expression:
var selectedHref = selections[selectedBook];
response = await httpClient.GetAsync(selectedHref);
content = await response.Content.ReadAsStreamAsync();
htmlDocument = new HtmlDocument();
htmlDocument.Load(content);
var price = htmlDocument.DocumentNode.SelectSingleNode(
"//*[@id=\"content_inner\"]/article/div[1]/div[2]/p[1]");
var table = new Table();
table.AddColumn("Title");
table.AddColumn("Price");
table.AddRow(selectedBook, price.InnerText);
AnsiConsole.Write(table);
Like in the previous example, we use HttpClient to get the content of the URL, and HtmlAgilityPack to query for the price element. If have used the Copy XPath feature in Chrome to illustrate how a generated XPath looks. Finally, I'm using the Table widget from Spectre.Console to output the title and price in a table structure. Let's run the code:
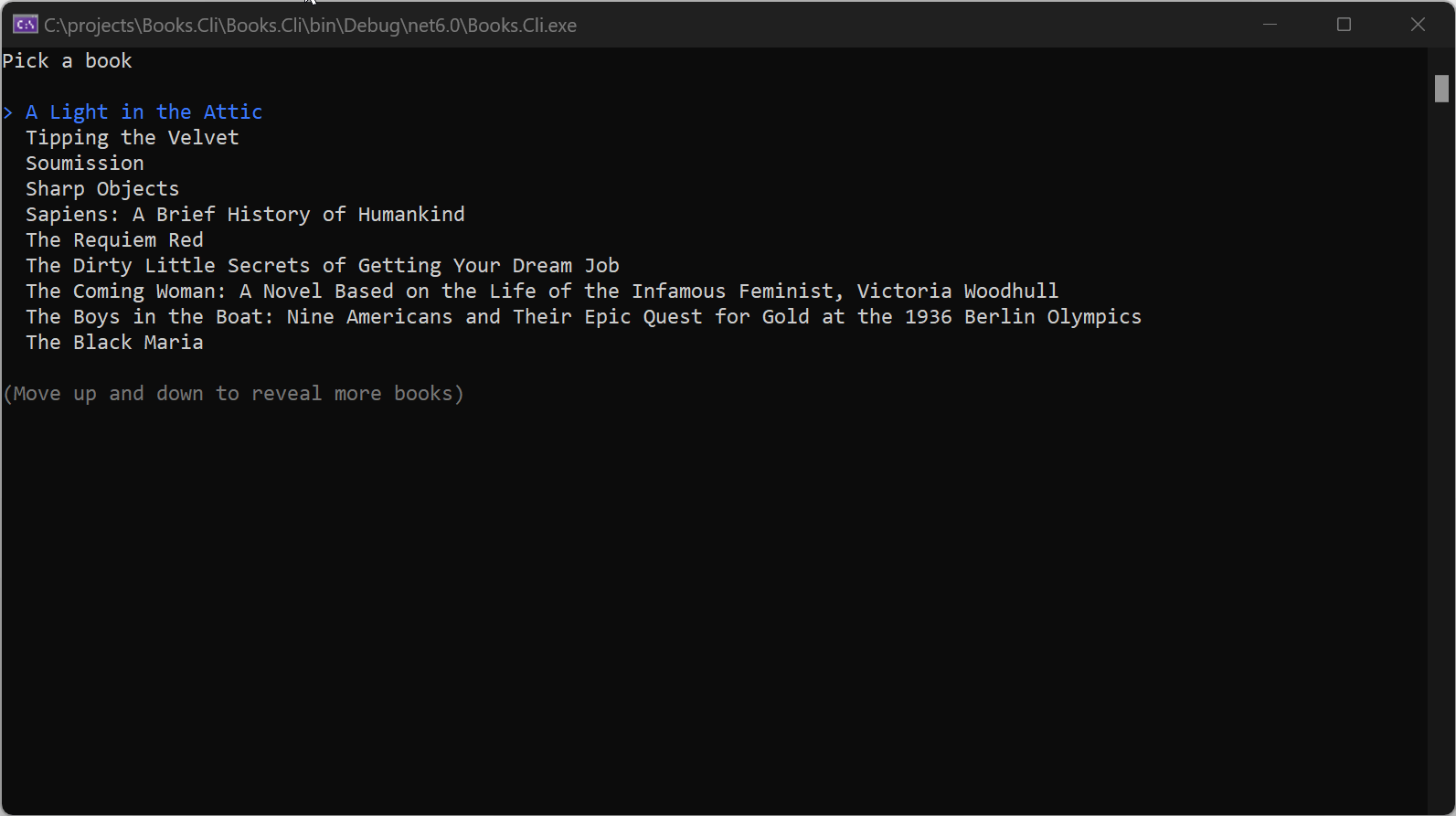
Sweet! Our very own Books CLI presents random books with imaginary prices.
To be fair to AngleSharp let's re-implement the code to support that framework instead. Start by installing the NuGet package:
dotnet add package AngleSharp
AngleSharp uses a slightly different approach to fetch the content:
var browsingContext = BrowsingContext.New(Configuration.Default.WithDefaultLoader());
var baseUrl = new Uri("https://books.toscrape.com/");
var document = await browsingContext.OpenAsync(baseUrl.AbsoluteUri);
The content of the URL is loaded into the document variable of type IDocument. This document corresponds the HtmlDocument provided by HtmlAgilityPack.
Next, we'll parse the list of books:
var selections = new Dictionary<string, string>();
var books = document.DocumentElement.QuerySelectorAll("article.product_pod");
foreach (var book in books)
{
var anchor = book.QuerySelector("div.image_container > a");
var href = anchor.GetAttribute("href");
var image = anchor.QuerySelector("img.thumbnail");
var alt = image.GetAttribute("alt");
selections.Add(alt, href);
}
var selectedBook = AnsiConsole.Prompt(
new SelectionPrompt<string>()
.Title("Pick a book")
.PageSize(10)
.MoreChoicesText("[grey](Move up and down to reveal more books)[/]")
.AddChoices(selections.Keys));
Notice that the query syntax is different from the previous example. Out of the box, AngleSharp uses CSS query selectors over XPath. Some people prefer them, while others really dig XPath. Like HtmlAgilityPack, there's an extension to work with both query syntaxes if you prefer one over the other.
The final step is to fetch the landing page of the selected book and present it in the same way as in the previous example:
var selectedHref = selections[selectedBook];
document = await browsingContext.OpenAsync(new Uri(baseUrl, selectedHref).AbsoluteUri);
var price = document.DocumentElement.QuerySelector(
"#content_inner > article > div.row > div.col-sm-6.product_main > p.price_color");
var table = new Table();
table.AddColumn("Title");
table.AddColumn("Price");
table.AddRow(selectedBook, price.TextContent);
AnsiConsole.Write(table);
Again, I have used the trick of copying the selector through Developer Tools in Chrome. You will need to pick Copy | Copy selector to copy the full CSS query selector.
I hope this will help getting started with scraping websites from C#. But remember getting permission from the author of the website, before going bananas on building your very own IMDb clone.
elmah.io: Error logging and Uptime Monitoring for your web apps
This blog post is brought to you by elmah.io. elmah.io is error logging, uptime monitoring, deployment tracking, and service heartbeats for your .NET and JavaScript applications. Stop relying on your users to notify you when something is wrong or dig through hundreds of megabytes of log files spread across servers. With elmah.io, we store all of your log messages, notify you through popular channels like email, Slack, and Microsoft Teams, and help you fix errors fast.

See how we can help you monitor your website for crashes Monitor your website