
Find anomalies with spike detection and ML.NET
We recently started experimenting with machine learning on elmah.io. There's a closed beta on anomaly detection and more, similar features will follow in the future. We chose ML.NET as the framework and are pretty happy with the results so far. The amount of documentation is good but mostly limited to flower detection samples (using the frequently used Iris data set). In this post, I'll share how we implemented anomaly/spike detection and which problems we ran into.

This is not an introduction post to machine learning. There are a lot of good resources out there, but I'll try to make sure that everyone can follow along.
There is a range of sub-areas within machine learning. For the rest of this post, I'll focus on anomaly/spike detection exclusively. So what is anomaly/spike detection all about?
Being able to log errors to a service like elmah.io is a great first step for all .NET developers. The next step is to get a good overview of the errors your applications are generating. This can be quite challenging. When you have a few errors generated every day, it's easy. But the complexity typically increases by the number of applications and lines of code you configure to log errors. anomaly/spike detection is a great way to help you with this process.
By letting machine learning crunch through your data, you can get a visual indication of a spike. A spike being something out of the ordinary (an anomaly). Looking at anomalies is a great way to identify when new errors are introduced and to help you classify the severity of different errors. Let's look at a real-life example from one of our logs:
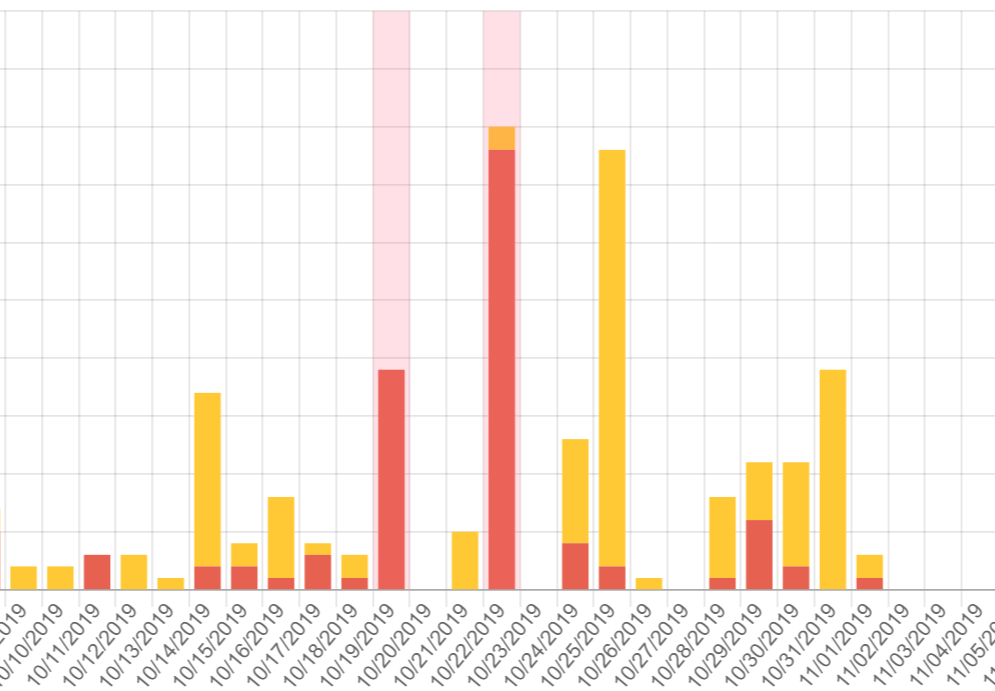
As seen on the chart, two bars are marked with a red background color which is our way to indicate an anomaly visually. If you look at the error count before 10/19/2019 they are limited to only a few instances per day, while we see a sudden spike on that day. We did introduce a bug that day which was fixed pretty quickly. The system then ran error-free for two days and a new bug was introduced (dough!). Again, the bug is indicated by a new spike on 10/22/2019.
By looking at the chart and the description above, I hope that it is clear for everyone what a spike is and why it can be called an anomaly.
You may have heard about model training in machine learning and ML.NET. When I started diving into ML.NET, training was the first step in most of the blog posts I read. Luckily, spike detection doesn't require any training, why the code is extremely simple. In short, you hand a time series to ML.NET and it outputs a list of predictions.
No more explaining. Let's look at some code! Start by installing the following NuGet packages:
Install-Package Microsoft.ML
Install-Package Microsoft.ML.TimeSeries
The Microsoft.ML package contains all of the core code and interfaces to use ML.NET. Microsoft.ML.TimeSeries contains the prediction engine for time-series data. To use ML.NET, you will need to create a new instance of MLContext. The context is similar to contexts known from Entity Framework.
var mlContext = new MLContext();
As a quick test, we'll generate an input that contains a spike:
var counts = new[] { 0, 1, 1, 0, 2, 1, 0, 0, 1, 1, 50, 0, 1, 0, 2, 1, 0, 1 };
See the spike? The value 50 stands out. Let's see if ML.NET agrees. We will need a strongly typed object as input to ML.NET:
class Input
{
public float Count { get; set; }
}
Like the input, ML.NET needs a strongly typed output class:
class Output
{
[VectorType(3)]
public double[] Prediction { get; set; }
}
The Output will include the prediction in a double array. Looking at the output for the first time, the code looks weird. How can an array of doubles with a VectorType attribute of 3 elements contain a prediction from a machine learning framework? Keep reading and we'll see in a minute.
Next, we will need an estimator. An estimator is an object that can be used to train a machine learning model (not interesting in this sample) and get a transformer needed to identify spikes:
var estimator = mlContext.Transforms.DetectIidSpike(
nameof(Output.Prediction),
nameof(Input.Count),
confidence:99,
pvalueHistoryLength:counts.Length / 4);
We call the DetectIidSpike-method part of the Microsoft.ML.TimeSeries package. The method takes 4 parameters. The names of the input and output properties that I already showed you, as well as two integers. confidence needs to be an integer in the range from 0 to 100. The higher the value, the more confident ML.NET needs to be if a value is a spike or not to output it as one. pvalueHistoryLength is somewhat of a magic value to me and I probably need to study machine learning more to fully understand this parameter (hey, at least I'm honest here 😂). Most spike detection tutorials set the value of pvalueHistoryLength to one-fourth of the input length, why I'll do the same for now.
Finally, time to get the transformer:
ITransformer transformer = estimator.Fit(mlContext.Data.LoadFromEnumerable(new List<Input>()));
The transformer is acquired by calling the Fit-method on the estimator that we fetched in a previous step. Notice how we send an empty list of Input objects to the method? The parameter for the Fit-method is used for training, which we don't need for spike detection.
With the transformer in hand, we can transform the input data to get the predictions from ML.NET:
var input = counts.Select(x => new Input { Count = x });
IDataView transformedData = transformer.Transform(mlContext.Data.LoadFromEnumerable(input));
The Transform-method expects an enumerable of objects conforming to the "schema" that we already gave ML.NET (nameof(Input.Count)). I'm using the LoadFromEnumerable-method once again, but this time with the list of integers instead of an empty list. If you're coding along, this is the input data you want a prediction on.
Only a single step left to get the predictions in a readable format:
var predictions = mlContext.Data.CreateEnumerable<Output>(transformedData, false);
In this step, I convert the output from Transform to an enumerable of Output objects as declared in a previous step. With this in hand, we can output the predictions:
foreach (var p in predictions)
{
Console.WriteLine($"{p.Prediction[0]}\t{p.Prediction[1]}\t{p.Prediction[2]}");
}
Remember the double array and the VectorType on the Output class? Here you see the output of that. Each entry in the predictions enumerable is an array of three doubles:
0 0 0,5
0 1 0,15865526383236372
0 1 0,2613750311936282
0 0 0,17796491136567605
0 2 0,011390874461660316
0 1 0,49999999975
0 0 0,16490956024045023
0 0 0,2804576814507901
0 1 0,4034750154990393
0 2 0,011390874461660316
1 50 1E-08
0 0 0,36323554577142725
0 1 0,377624053546577
0 0 0,36323554577142725
0 2 0,4013610122501119
0 1 0,4034750154990393
0 0 0,16490956024045023
0 1 0,4034750154990393
The first column is a bit indicating if the entry is a spike or not. 0 means no and 1 means yes. The second column is the original input. And the third and final column is a calculated confidence value. The lower the number, the more likeable the input is a spike. When looking at the output we see the value of 50 being the only spike.
Here's the full code so far:
var counts = new[] { 0, 1, 1, 0, 2, 1, 0, 0, 1, 1, 50, 0, 1, 0, 2, 1, 0, 1 };
var mlContext = new MLContext();
var estimator = mlContext.Transforms.DetectIidSpike(nameof(Output.Prediction), nameof(Input.Count), confidence:99, pvalueHistoryLength:counts.Length / 4);
ITransformer transformer = estimator.Fit(mlContext.Data.LoadFromEnumerable(new List<Input>()));
var input = counts.Select(x => new Input { Count = x });
IDataView transformedData = transformer.Transform(mlContext.Data.LoadFromEnumerable(input));
var predictions = mlContext.Data.CreateEnumerable<Output>(transformedData, false);
foreach (var p in predictions)
{
Console.WriteLine($"{p.Prediction[0]}\t{p.Prediction[1]}\t{p.Prediction[2]}");
}
At first glance, the code may look a bit over-engineered. But remember that ML.NET can be used for multiple purposes and the flow is pretty much the same if you train a model or not.
Let's play with the settings. Remember the confidence parameter with the value of 99? By specifying such a high value, ML.NET needs a very high confidence when making the judgement call whether an input is a spike or not. Let's change it to 95 and see what happens:
var estimator = mlContext.Transforms.DetectIidSpike(
nameof(Output.Prediction),
nameof(Input.Count),
confidence:95,
pvalueHistoryLength:counts.Length / 4);
With the same input, the predictions now looks like this:
0 0 0,5
0 1 0,15865526383236372
0 1 0,2613750311936282
0 0 0,17796491136567605
1 2 0,011390874461660316
0 1 0,49999999975
0 0 0,16490956024045023
0 0 0,2804576814507901
0 1 0,4034750154990393
0 1 0,2613750311936282
1 50 1E-08
0 0 0,368076688458975
0 1 0,38239457274913025
0 0 0,368076688458975
0 2 0,4013610122501119
0 1 0,4034750154990393
0 0 0,16490956024045023
0 1 0,4034750154990393
Notice the difference? The fifth element (value of 2) is now marked as a spike too.
Which value to use for confidence is totally up to your case and input value. Play around with different values and be the judge of what produces the best results for you.
One thing I came across while implementing spike detection for elmah.io is what may or may not be a bug. Let's change the input values to the following:
var counts = new[] { 1, 3, 0, 4, 5, 5, 4, 3, 3, 0, 13, 8, 1, 61, 21, 40, 7, 7, 5, 6, 8, 33, 11, 5,
2, 10, 11, 18, 14, 23, 8, 17, 15, 13, 24, 29, 15, 20, 29, 19, 18, 17, 23, 47, 7, 14, 26, 28,
5, 22, 47, 22, 20, 9, 40, 6, 8, 4, 10, 10, 1, 4, 27, 3, 3, 7, 6, 12, 8, 3, 1, 2, 0, 0, 2, 0,
2, 0, 0, 0, 4, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 2 };
Spotting anomalies manually and without the help of ML.NET is now a whole lot harder. Here's part of the result:
0 1 0,5
0 3 0,022750062887256395
0 0 0,08000261555683919
0 4 0,07336260731420347
0 5 0,09324626262574676
0 5 0,19087154278882695
0 4 0,37936589390701053
0 3 0,4522491125423572
0 3 0,4543375551070543
0 0 0,09656461688070728
0 13 7,231836548493575E-07
0 8 0,16279622550878553
0 1 0,26866445055948984
0 61 1E-08
0 21 0,19532181235194518
0 40 0,07628985932177507
0 7 0,4814184562065965
0 7 0,4835626729623246
0 5 0,44158539201429914
0 6 0,467300428950856
0 8 0,48429199889094554
0 33 0,11185621221616127
0 11 0,4415187627738487
0 5 0,4219793790334213
0 2 0,34845080975673626
0 10 0,4668402175020555
0 11 0,45435592220182563
0 18 0,3164680969641882
0 14 0,4109081873786849
0 23 0,25204845788437136
0 8 0,4222073383577716
0 17 0,38281677839584366
0 15 0,4397732642572547
0 13 0,49932909372608614
0 24 0,26998351731163683
0 29 0,2086753725973
0 15 0,4965672805299245
0 20 0,32702008169487357
0 29 0,14736951748986427
0 19 0,3341649373312337
0 18 0,3817593360276714
0 17 0,4308978322639091
0 23 0,25778090864274994
1 47 0,0025041522676845784
The last line with the value of 47 is marked as a spike. When looking at the previous counts and the pattern in the data, 47 definitely looks like an anomaly. But take a look at line number 14. With value from 0 to 13 before it, 61 definitely looks like an anomaly as well. ML.NET seems to have a problem with confidence values lower than 0.05. StackOverflow suggested this quickfix:
if (p.Prediction[2] < (1 - 0.95))
{
p.Prediction[0] = 1;
}
It's a bit of a hack, but it gets the job done:
0 1 0,5
1 3 0,022750062887256395
0 0 0,08000261555683919
0 4 0,07336260731420347
0 5 0,09324626262574676
0 5 0,19087154278882695
0 4 0,37936589390701053
0 3 0,4522491125423572
0 3 0,4543375551070543
0 0 0,09656461688070728
1 13 7,231836548493575E-07
0 8 0,16279622550878553
0 1 0,26866445055948984
1 61 1E-08
The downside here is that more input values are marked as spikes. I hope to be able to come up with a better fix or for Microsoft to make this work properly.
What do you think? Could ML.NET and machine learning be used to look at your data? Let us know if you want to play around with the closed beta of anomaly detection on elmah.io.
elmah.io: Error logging and Uptime Monitoring for your web apps
This blog post is brought to you by elmah.io. elmah.io is error logging, uptime monitoring, deployment tracking, and service heartbeats for your .NET and JavaScript applications. Stop relying on your users to notify you when something is wrong or dig through hundreds of megabytes of log files spread across servers. With elmah.io, we store all of your log messages, notify you through popular channels like email, Slack, and Microsoft Teams, and help you fix errors fast.

See how we can help you monitor your website for crashes Monitor your website