
16 common mistakes C#/.NET developers make (and how to avoid them)
As developers, we often fall into common pitfalls that impact the performance, security, and scalability of our applications. From neglecting data validation to overengineering, and from ignoring async/await to mishandling resource disposal, even experienced C# developers can make these mistakes. In this post, I've gathered some of the most frequent issues developers encounter in C# and how to avoid them with practical solutions.

Doing everything on your own instead of using libraries
Sometimes, developers waste their time and energy resolving problems that have already been solved in a better way. Before reinventing the wheel, consider searching for a well-tested library that already solves your problem.
The .NET DI container, DataAnnotations, Math, and many other NuGet packages provide features in a more manageable way. You can leverage your application and optimize time for business logic rather than rewriting the same things yourself.
Ignoring async/await
This is probably one of the most critical aspects every developer should consider in their application. I/O operations and DB queries block the thread until they complete, which keeps the application idle. If the thread is blocked and another operation tries to run on it, it may result in exceptions or unresponsive behavior. With async/await, it does not block the thread and allows operations to run in parallel.
public async Task<List<JobPost>> GetJobPostsAsync()
{
using var dbContext = _dbContextFactory.CreateDbContext();
return await dbContext.JobPosts.ToListAsync();
}Organising code in technical directories
Grouping files solely by technical roles, such as Controllers, Services, and repositories, can be problematic in development.

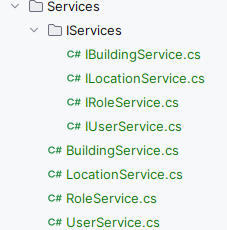
In such a structure, you may waste additional time getting to a class during debugging or adding new features.
In addition to the current directory structure, organise the code by feature and domain.
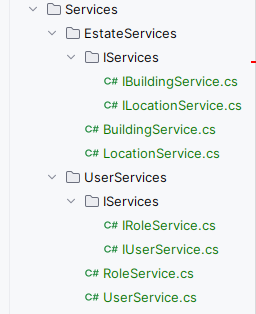
This improves code navigation and increases development speed. Next time you encounter an issue, you have a better chance of knowing where to navigate. Alternatively, when adding a new feature, simply go to the relevant folder for the domain.
Over-engineering solutions
Many developers do not thoroughly study their applications and attempt to fit information into the applications they read. Adding everything can make the project unnecessarily complicated and slow down the development process. Introducing layers, abstractions, and patterns can sometimes be a good decision, but can make code more challenging to maintain.
Begin with a straightforward approach, focusing on the current issue. Introduce any pattern or layer only when real requirements demand them. Abstract only complex implementations. Follow KISS (Keep It Simple, Stupid) and SOLID only when it serves a benefit. If you are starting a feature or project, focus on the core functionality and reserve optimization for later. Sometimes, optimization adds confusing layers and affects the actual feature; hence, apply them after analyzing properly.
Rethrowing exceptions incorrectly
One common mistake many developers ignore is rethrowing an exception. See the following code as an example:
void IsCustomer(string role)
{
try
{
if (role.Equals("Customer"))
throw new Exception("Invalid role");
Console.WriteLine("It is customer");
}
catch (Exception e)
{
Console.WriteLine(e);
throw e;
}
}
IsCustomer("Admin");
In the output, you can see that an exception is thrown twice. One because throw new Exception("Invalid role") and the second, when the catch block throws e. While debugging, this leads to confusion about the line number.
To improve the readability of the stack trace, just throw the exception like this:
void IsCustomer(string role)
{
try
{
if(role.Equals("Customer"))
throw new Exception("Invalid role");
Console.WriteLine("It is customer");
}
catch (Exception e)
{
Console.WriteLine(e);
throw;
}
}The code preserves the source location from which the exception originated.

For more exception best practices, check out the following post: C# exception handling best practices.
Not applying validations
Ignoring input validations can lead to serious problems, such as runtime exceptions, security vulnerabilities, and data inconsistencies. Unchecked or invalid data may slip through, potentially resulting in attacks (like SQL injection 😨), unexpected logic errors, or compromised data integrity.
The System.ComponentModel.DataAnnotations namespace provides attributes for data validation. The attributes assume all the incoming data is incorrect, hence enforcing validation on it:
using System.ComponentModel.DataAnnotations;
public class CreateBuildingRequest
{
[Required(ErrorMessage = "Building name is required.")]
[StringLength(50, ErrorMessage = "Building name cannot exceed 50 characters.")]
public string Name { get; set; }
[Required(ErrorMessage = "Area is required.")]
[Range(0.01, double.MaxValue, ErrorMessage = "Area must be greater than 0.")]
public decimal Area { get; set; }
}Accidental multiple enumerations with yield
Consider the following example:
IEnumerable<int> GetSeries()
{
Console.WriteLine("Series started");
yield return 1;
yield return 2;
yield return 3;
}
// Usage
var series = GetSeries();
if (series.Any())
{
Console.WriteLine("----");
Console.WriteLine($"Count {series.Count()}");
foreach (var item in series)
{
Console.WriteLine($"Current: {item}");
}
}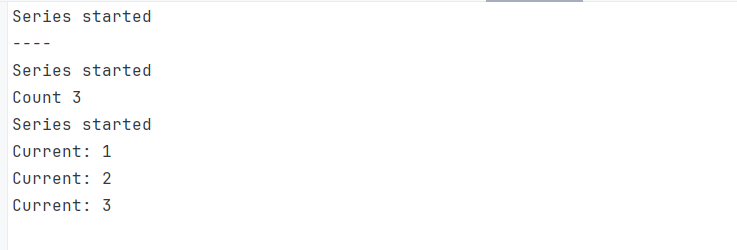
The above code brings a performance caveat and a logical issue, as seen in the output. The IEnumerable<int> is created by yield return, and each enumeration restarts the generator and re-runs the logic from the beginning, as you can see in multiple printings of the Series started. When we call Any(), Count(), and foreach with the series IEnumerable, the GetSeries method is called, hence multiple executions of all the code in GetSeries.
Make the series a list:
var series = GetSeries().ToList(); // Evaluated once;yield return Creates a lazy sequence that starts over again on every iteration. By calling ToList, we run once and store all results.
Incorrect resource disposal
Properly disposing of memory and other resources improves memory management and prevents leaks. Objects such as database connections, file streams, and network sockets implement the IDisposable interface. Ensure that you employ an explicit cleanup strategy to free resources after use.
One recommended way to cope with the issue is the following:
using (var file = new FileStream("germanNames.txt", FileMode.Open))
{
// Use the file here
byte[] buffer = new byte[75];
file.Read(buffer, 0, buffer.Length);
}
// File is automatically closed and disposed of hereC# 8.0 or later introduces it more cleanly:
using var stream = new FileStream("germanNames.txt", FileMode.Open);
// Use the stream
byte[] buffer = new byte[75];
file.Read(buffer, 0, buffer.Length);Inefficient string concatenation
The concatenation of strings can also affect an application's performance. Consider the example where we are concatenating 100.000 strings:
string BuildLoop(IEnumerable<string> names)
{
string result = string.Empty;
foreach (var item in names)
{
result += item + ", ";
}
return result;
}
// Test
using System.Diagnostics;
var names = Enumerable
.Range(0, 100000)
.Select(x => "Gul")
.ToList();
var stopwatch = Stopwatch.StartNew();
var result = BuildLoop(names);
stopwatch.Stop();
Console.WriteLine($"{stopwatch.ElapsedMilliseconds} ms");
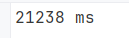
Notice the time taken is 21 seconds. To improve performance, let's use StringBuilder:
string BuildLoop(IEnumerable<string> names)
{
var result = new StringBuilder();
foreach (var item in names)
{
result.Append(item);
}
return result.ToString();
}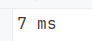
Note how drastically execution time has dropped for the same operation.
Comparing strings with improper methods
In many projects, programmers apply string comparison with == that somehow does the job, but is not recommended. C# does not identify what type to compare when using ==:
if (role == "Customer")A dedicated string comparison is public bool Equals(string value) that performs byte-to-byte comparison:
if (role.Equals("Customer"))The Equals method performs a case-sensitive comparison. It has a case-insensitive alternative, which is the public bool Equals(string value, StringComparison.OrdinalIgnoreCase) method:
if (role.Equals("Customer"), StringComparison.OrdinalIgnoreCase)Inefficient definition of the HttpClient lifecycle
This is a repeating subject that is already described in hundreds of blog posts. Unfortunately, this issue still shows up. Consider the following code:
using System.Diagnostics;
async Task MakeClientRequestAsync(string url)
{
using (var client = new HttpClient())
{
try
{
var stopwatch = Stopwatch.StartNew();
await client.GetAsync(url);
stopwatch.Stop();
Console.WriteLine($"Client request executed successfully in {stopwatch.ElapsedMilliseconds} ms");
}
catch (Exception e)
{
Console.WriteLine(e);
throw;
}
}
}
for (int i = 0; i < 1000; i++)
{
await MakeClientRequestAsync("https://www.endersen.com/");
}

The problem is that the MakeClientRequestAsync method creates and disposes of an HttpClient each time in a quick session, which leads to port exhaustion. The HTTP connection enters the TIME_WAIT state when it is not in use.
Almost always, instantiate the HTTP connection once. It's better to do this in a web or desktop application using dependency injection:
var client = new HttpClient();
async Task MakeClientRequestAsync(string url)
{
try
{
var stopwatch = Stopwatch.StartNew();
await client.GetAsync(url);
stopwatch.Stop();
Console.WriteLine($"Client request executed successfully in {stopwatch.ElapsedMilliseconds} ms");
}
catch (Exception e)
{
Console.WriteLine(e);
throw;
}
}
Now, the execution time is significantly lower for each call, in fact, it is halved. Instantiating HttpClient not only improves performance but also eliminates application crashes caused by frequent port assignments and unassignments.
Using imperative statements in data manipulation, ignoring declarative counterparts
Manual iterations of collections are common among developers. Sometimes, we write less maintainable and unnecessarily more prolonged statements for simple operations. See this code that sums a total of all account balances:
decimal totalAmount = 0;
foreach (Account account in bankAccounts)
{
if (account.IsActive is true)
{
totalAmount += account.Balance;
}
}The problem is that the code looks messy, and imagine if some other filters are involved, how dirty it will become.
Using LINQ, the code can be written without the need for multiple nested structures. A major advantage of using LINQ is its readable and cleaner code. We can simplify our example using LINQ like this:
decimal total = (from account in bankAccounts
where account.IsActive
select account.Balance).Sum();It's probably up for discussion, but IMO this approach is cleaner and understandable.
Accidental variable capture in lambdas
Lambdas in C# utilize closure capture, which captures variables by reference, not by value. This is the default behaviour of lambdas and anonymous methods.
For example:
var actions = CreateActions();
foreach (var action in actions)
{
action();
}
List<Action> CreateActions()
{
List<Action> actions = new List<Action>();
for (int i = 0; i < 3; i++)
{
actions.Add(() => Console.WriteLine("Action " + i));
}
return actions;
}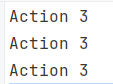
All the iterations use the latest value of the variable i, which is not what we want in this example. Let's fix it by introducing a local value:
List<Action> CreateActions()
{
List<Action> actions = new List<Action>();
for (int i = 0; i < 3; i++)
{
int copy = i; // Capturing the current value
actions.Add(() => Console.WriteLine("Action " + copy));
}
return actions;
}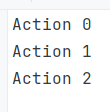
Here, we introduced a local variable for each iteration. Hence, each lambda references a separate variable and operates on that value.
Incorrect usage of Struct
Since structs are value types, they don't reflect the changes in a struct instance. Let me make the statement more straightforward with an example:
var holder = new CarHolder();
Console.WriteLine(holder.ReadonlyOrigin.Speed);
holder.ReadonlyOrigin.Accelerate(20);
Console.WriteLine(holder.ReadonlyOrigin.Speed);
public class CarHolder
{
public readonly SuperCar ReadonlyOrigin = new SuperCar { Speed = 0 };
}
public struct SuperCar
{
public double Speed { get; set; }
public void Accelerate(int speed) => Speed += speed;
}
When the holder is initiated, the ReadonlyOrigin field of the struct SuperCar is initialized. Upon calling Accelerate, C# creates a new instance of SuperCar and changes it. However, that is immediately lost after execution completes.
To mutate structs correctly, don't make the holder field read-only:
public class CarHolder
{
public SuperCar ReadonlyOrigin = new SuperCar { Speed = 0 };
}
Using mapping libraries
Mapping packages such as AutoMapper are widely known for their concise and neat code. They enclose the mapping between DTOs and other models in a separate profile class, reducing boilerplate code in the main code. However, this simplicity comes with a tradeoff in maintainability. Any mismatch in the source and destination classes results in runtime errors. Besides, it adds complexity when the model is updated or contains nested objects.
Manual mapping provides you with more control and flexibility for complex models. Although it is verbose, with AI tools, you can write it faster than before. For any updates, you don't need to navigate the mapping class or profiles. Also, errors are mostly identified at runtime or even by IntelliSense.
Neglecting Code Readability and Standards
Sometimes developers consider coding standards and consistency as a minor concern. However, what seems small initially can become a nightmare during debugging and maintenance.
Although writing standard code may take a bit more time upfront, it is fruitful when your project grows and multiple teams work on it. Clear naming, consistent formatting, and adherence to principles such as SOLID, DRY, and KISS make the codebase more readable, maintainable, and less prone to errors. Consider using static code analyzers and features within your IDE to spread out a set of coding principles throughout your organization or team.
Conclusion
Even experienced developers can fall into common traps that hurt performance, security, or maintainability. In this post, we explored 16 of the most frequent mistakes C# developers make and how to avoid them with simple, practical solutions. Keeping these in mind will help you write cleaner, faster, and more robust code across .NET projects.
elmah.io: Error logging and Uptime Monitoring for your web apps
This blog post is brought to you by elmah.io. elmah.io is error logging, uptime monitoring, deployment tracking, and service heartbeats for your .NET and JavaScript applications. Stop relying on your users to notify you when something is wrong or dig through hundreds of megabytes of log files spread across servers. With elmah.io, we store all of your log messages, notify you through popular channels like email, Slack, and Microsoft Teams, and help you fix errors fast.

See how we can help you monitor your website for crashes Monitor your website